

外観検査とグレーゾーン
1.外観検査自動化で判定パラメータの落としどころが見つからない…
官能検査の自動化をすすめていると、判定の難しいケース(良品と不良品(以降、OK と NG と表記します)の区別が難しい、検査員でも判定が割れるケース)が出てきて困ることがあります。
まずは閾値などのパラメータで微調整をしてみて意図通りの判定になるように試みますが「あちらを立てればこちらが立たず・・・なかなかうまい落としどころが見つからない・・・」といった経験をされた方も多いのではないでしょうか?
ISP も gLupe を使った外観検査自動化を数多く手がけてきておりますが、こういった判定の難しいケースに遭遇することは少なくありません。
本記事では、判定の難しいケースはどのようなものが多いのかを整理したうえで、現実的にはどう扱っていくと落としどころが見つかりやすいのか、の一例をご紹介します。
本記事ではカメラセンサを使った画像データからの外観検査を前提としています。
以降、検査画像データを画像データと表記します。
まずは製品詳細資料をダウンロード
無料で資料をダウンロード
判定の難しいケースとグレーゾーン
判断の難しいケースには以下のようなパターンがあります。
- OK/NG の画像データが似ている(でも人が見ても OK/NG の区別はつく)
- 画像データがとても似ている、というかほぼ同じ(人が見ても区別がつかない)だけど、ひとつに OK、もう一つに NG のラベルがついている
- NG がそもそも画像データに写っていない
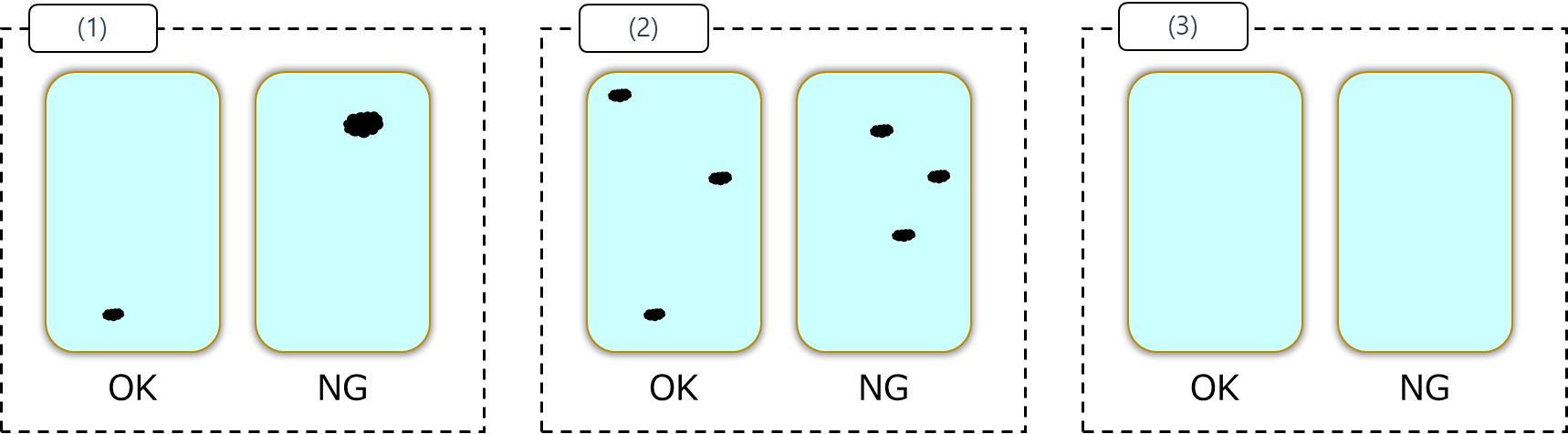
(1) は比較的理想的なパターンですね。
画像データが似ていても人で判断できる程度であれば、前処理の工夫や教師画像データの選定である程度の精度向上、落としどころは見つかりそうです。
(3) のような画像データに写ってない NG は残念ながら見つけられません。
「撮像機器の選定からやり直しですね!」とちゃぶ台返しになるのでここでは考えません・・・
厄介なのが (2) です。どちらもほとんど見た目が同じ画像データに、異なるラベルがついているパターンです。
本記事ではこの画像データのことをグレーゾーンの画像データ、もしくはグレーゾーンと呼ぶことにします。
こういったグレーゾーンが評価画像データに含まれている場合、どのような結果となるでしょうか?
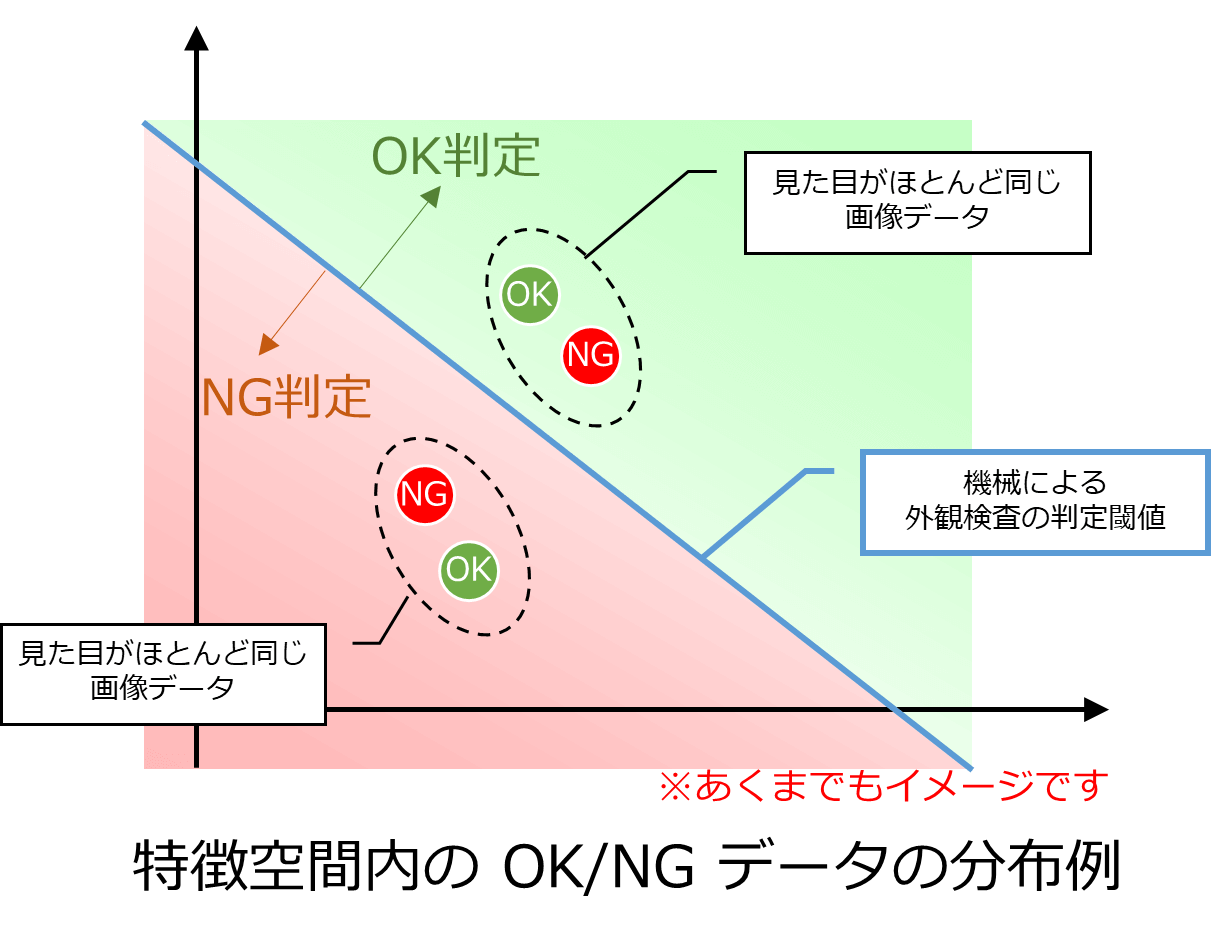
(外観検査を自動で行うための)機械は画像データの見た目のみで判断を行うため、ほぼ同じ見た目の画像データに対しては同じ結果を返します。
(2) のケースではほぼ同じ見た目の画像データに OK と NG のラベルがついている状態ですので、閾値をどんなに頑張って調整してもどちらも OK か、どちらも NG と判定されてしまいます。
閾値をどんなに頑張って調整しても、思った通りに判定してくれない理由はこういったところにあります。
まずは製品詳細資料をダウンロード
無料で資料をダウンロード
グレーゾーンはどうして生まれる?

ここでいったん冷静になってみると、見た目がほぼ同じ画像データに OK と NG のラベルがついていることがおかしくて、検査基準をはっきりさせて全画像データに対してしっかりラベルを付けていけばグレーゾーンはなくせるのではないか?とも考えられます。
検査基準を明確にして、基準に従ったラベルをつけていけばグレーゾーンはなくなるはず。
ラベル付けする対象の画像データが10枚ならグレーゾーンはなくせるはずでしょう。
100枚画像データなら・・・
頑張ればきっとできるはずです。
1,000枚の画像データなら・・・
ちょっと自信がなくなってきます。
10,000枚の画像データらなら・・・
うーん、自分はできないかもしれないけど熟練した検査員ならできるはず??
「ラベル付けを人間が実施する」という事実を前提とすると状況は変わってきますね。
もちろん熟練の(現場では神とあがめられるような)検査員がラベル付けを実施するとしても、作業環境や体調、疲労度、メンタル状況などによって判断が揺らぐ、ばらつくというのは官能検査ではよく知られた事実です。
検査員の熟練度でも結果が変わってきます。
ラベル付け対象の画像データが非常に簡単である場合(例えば画像データにワークが写っているか(OK)、そうでないか(NG))であれば、人間の判断が揺らいでもそれほど影響はないと思いますが、一般的な難易度の高い外観検査の課題を考えると、人間の判断の揺らぎ・ばらつきはラベル付けの結果にも影響することが容易に想像できます。
ここで ISP で取り扱った外観検査自動化のプロジェクトでの例を紹介しましょう。
ISP で外観検査自動化を取り扱う場合、お客様に画像データのラベリングを行っていただくのですが、その中で複数の検査員の方に同じ画像データのラベル付けをしてもらうことがあります。
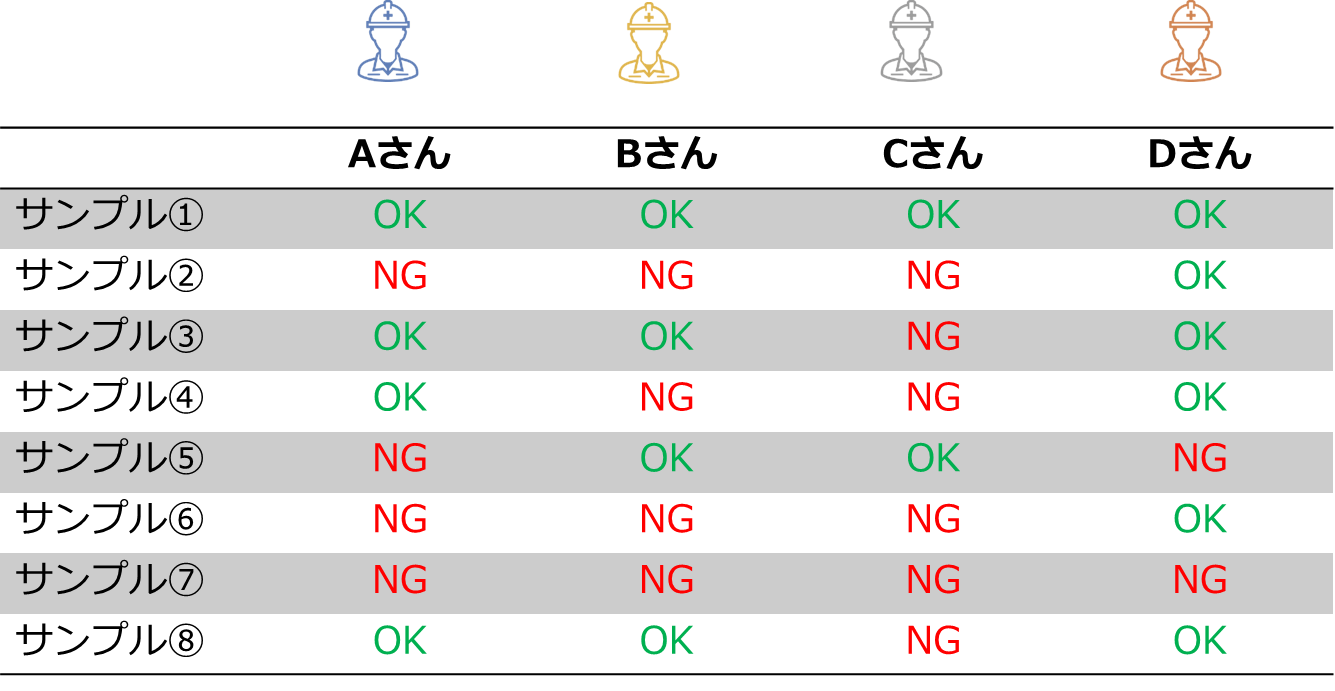
外観検査対象のワークを目視で確認する検査作業とワーク画像データのみを見てのラベリング作業には差があるので、ある程度のばらつきは発生するものと思っていたのですが、
思ったよりも検査員の間でラベルが異なるケースがありました。
たとえば、最初に「これは不良品(NG)です」とご提供いただいた画像データに誰も NG を付けなかった・・・ということもありました。
また、検査員の間で OK/NG の判断が割れるワーク画像データもでてきていて、内容を確認すると人間が見てみても判断の難しいものが多く含まれていました。
お客様にラベリングしてもらった画像データは ISP 側でもかならず確認するのですが、画像データの並びがラベリング結果に影響するケースもあるのではないかと考えています。
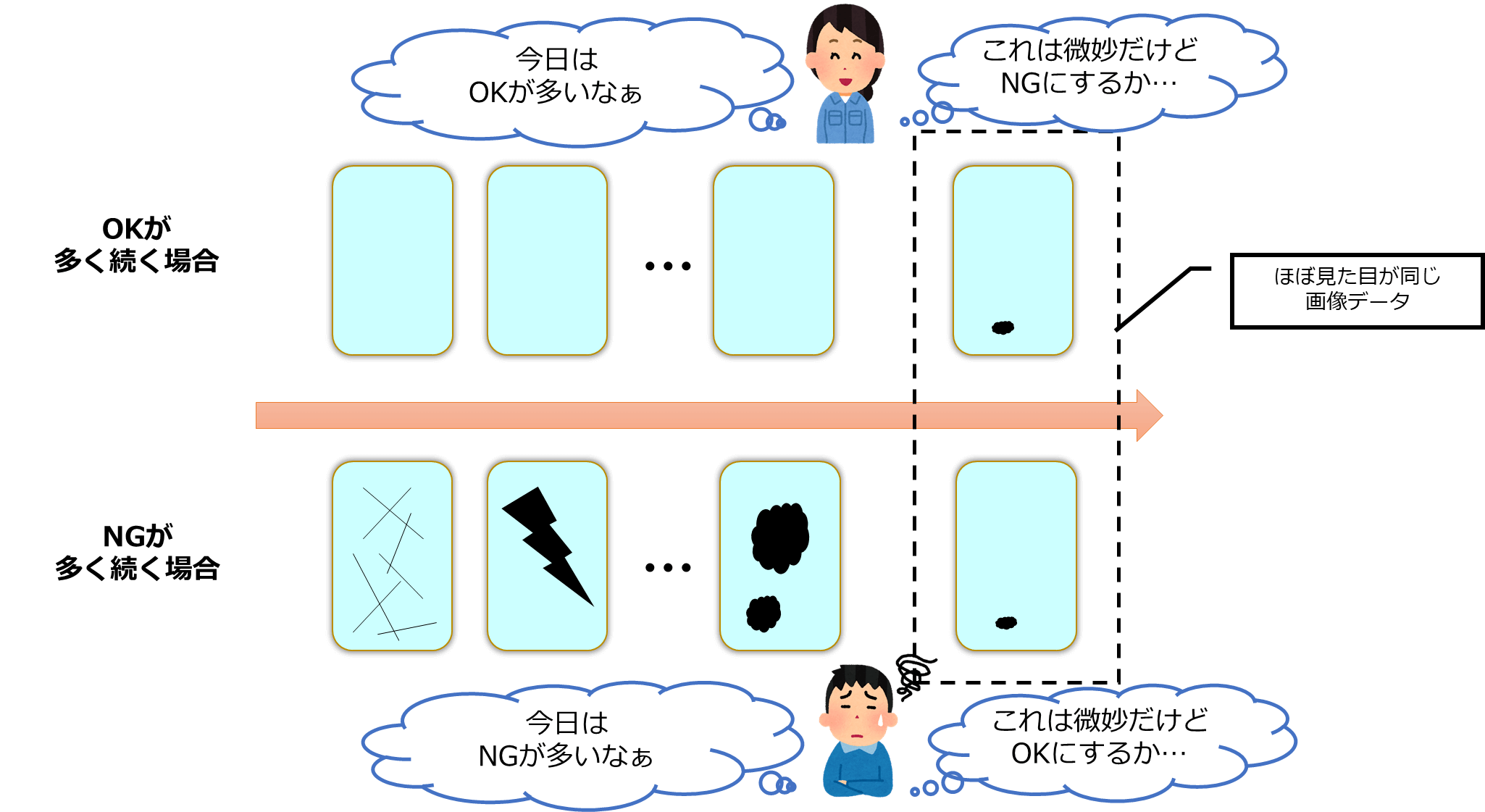
もちろんラベリングしている方は意図的に基準を変えているのではなく無意識だと思います。
「人間は全体を見て判断できる」といえば聞こえはいいのですが、判断の基準がぶれてしまうのは品質管理の面からは望ましくはありません。
このように大量の画像データを人間がラベル付けする場合には、同じ画像データに対してある程度のラベルのばらつき(グレーゾーン)が発生してしまうことが見えてきました。
このようなグレーゾーンが避けられないものと仮定すると、どのように扱っていけば良いのでしょうか?
まずは製品詳細資料をダウンロード
無料で資料をダウンロード
4.グレーゾーンはどうあつかう?
ここからはラベルのばらつき(グレーゾーン)を中心に画像データ全体を見ていくことにしましょう。
ラベル付けする画像データの中には明らかに OK/NG の画像データも含まれています。
不良が全くないきれいなパターンや、大きな不良がしっかり写っているようなパターンですね。
これらの画像データはとても分かりやすいので、ラベル付けしてもラベルのばらつきは大きくないと想定されます。
画像データ全体を複数人でラベル付けを行うと仮定して、NGラベルの数で画像データを並べていくと以下のように分布することが見えてきます。
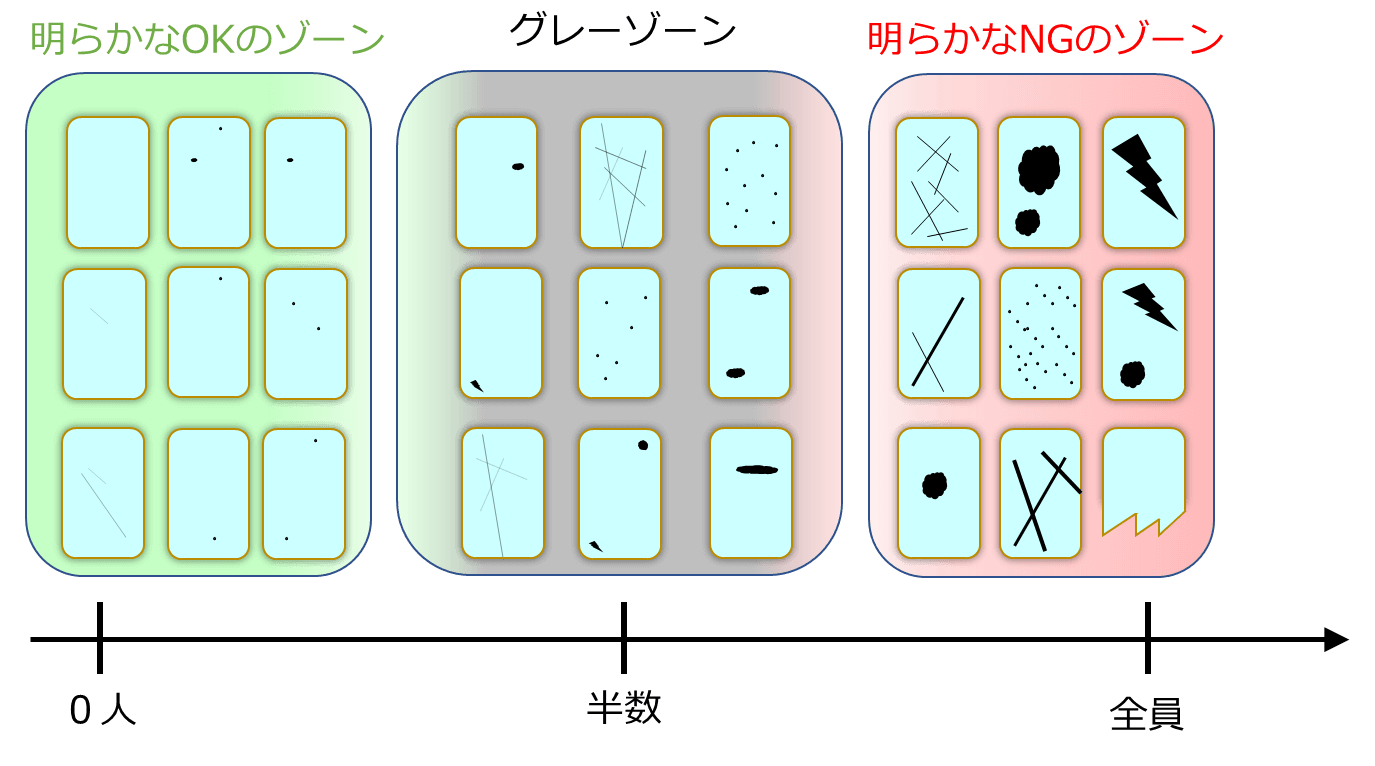
右から明らかなOKのゾーン、OK/NGの判定が分かれるグレーゾーン、明らかなNGのゾーンです。
明らかなOK/NGのゾーンでは、例えば10人の検査員にラベル付けをしてもらっても9-10人はOK/NGを間違いなくつけるだろうという画像データが集まっているイメージ、
OK/NGの判定が分かれるグレーゾーンでは10人中2ー8人がOK/NGを付けるような画像データが集まっているイメージです。
言い換えると、グレーゾーンの画像データは「ラベルが確率的に決まる」といってもいいかもしれません。
実際にどこまでを NG として扱うかは、歩留まりも考慮しながら、この図の中でどこから右端までをNGとして扱うのかの調整となるでしょう。
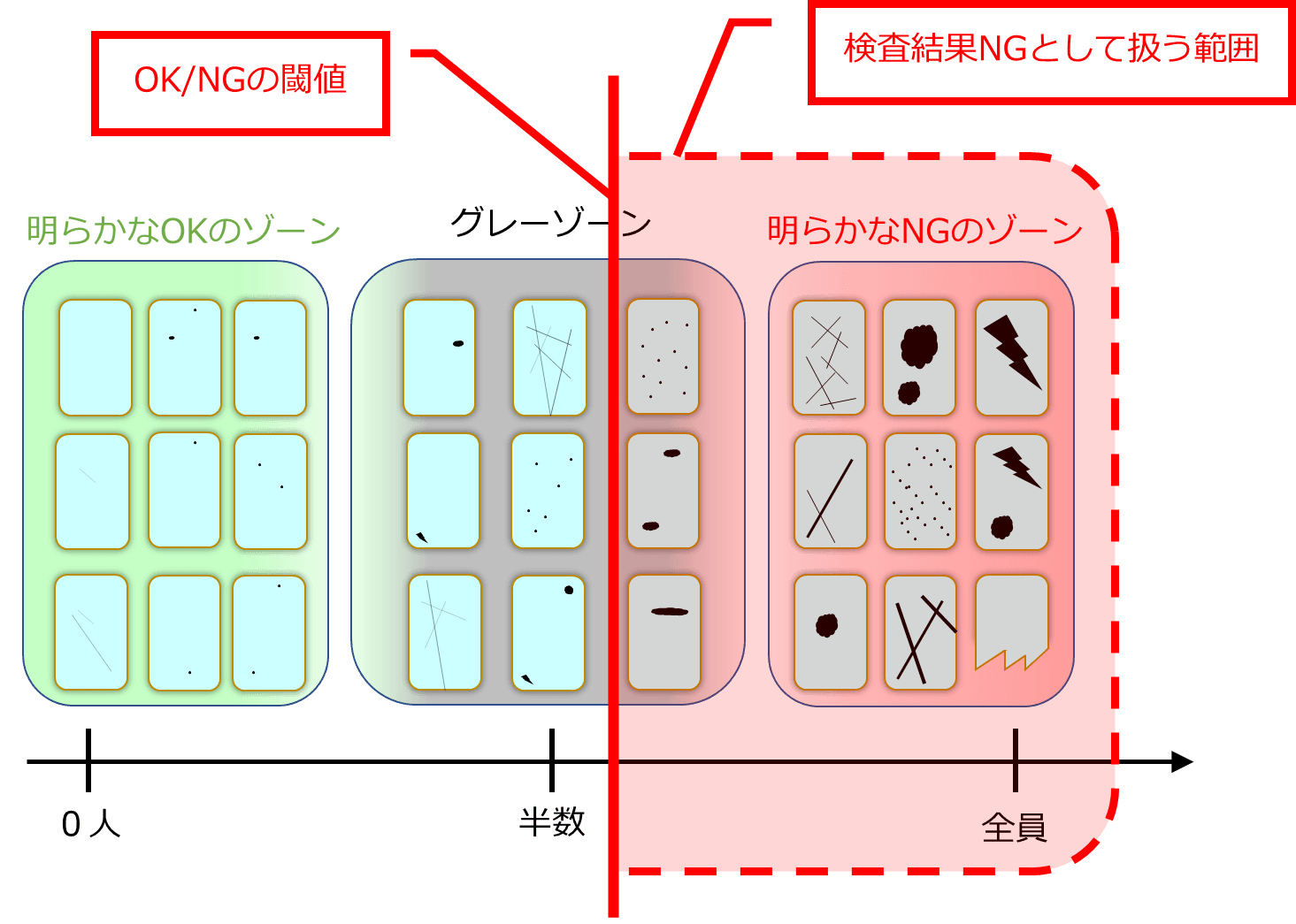
グレーゾーンを多く含む画像データを外観検査アルゴリズムで自動判定することを考えていくと、外観検査アルゴリズムが扱う課題は「画像データに対するOK/NGの分類問題」ではなく
「画像データに対するNGの確率(人がNGと判定する確率)を推定する回帰問題」ととらえるほうが自然だと考えられます(グレーゾーンが小さい場合は分類問題ととらえても良いと思います)。
このあとは、グレーゾーンを多く含む画像データに対する外観検査アルゴリズム開発をどう進めていくとよいのか(アルゴリズムをどう評価すればよいのか)を考えていきます。
グレーゾーンが多い場合の外観検査アルゴリズム開発と評価
ここからは、画像データにグレーゾーンが多く含まれるケースの外観検査アルゴリズム開発と評価の進め方の一例を紹介していきます。
この進め方は外観検査アルゴリズムにAI/Deep Learningを用いた手法だけではなく、画像処理による手法にも適用可能です。
全体の流れは以下となります。これまでと変わりませんね。
- 画像データ(評価画像データ)の準備
- 外観検査アルゴリズム開発と評価
各項目を詳しく見ていきましょう。
1. 画像データ(評価画像データ)の準備
まずは画像データを用意します。この画像データはアルゴリズム開発とアルゴリズム評価で使用するものです。
撮像機器の準備が整っていなければ、不良箇所をうまく写すための照明やカメラも選定し、撮像機器を製造ラインに設置して画像データを集めていきましょう。
そして、集めた画像データにラベルを付けていきます。
全ての画像データが明らかな OK/NG だけであれば OK/NG のラベルをつけていけばよいのですが、おそらく判断に迷うような画像データも出てきます。
その場合はグレーゾーンというラベルを付けておきましょう。
複数人でラベリングを行うことができるのであれば、多数決で OK/NG/グレーゾーンを振り分けてもよいでしょう(「判断に迷う」という判断にもばらつきが含まれますので、
ISP 的には複数人でのラベリングがおすすめです)。
ただし、複数人でラベリングを行う場合は基準をすり合わせておくこと、各人が個別にラベリングすること(相談しながらのラベリングはダメ)がとても重要です。
まずは製品詳細資料をダウンロード
無料で資料をダウンロード
2. 外観検査アルゴリズム開発と評価
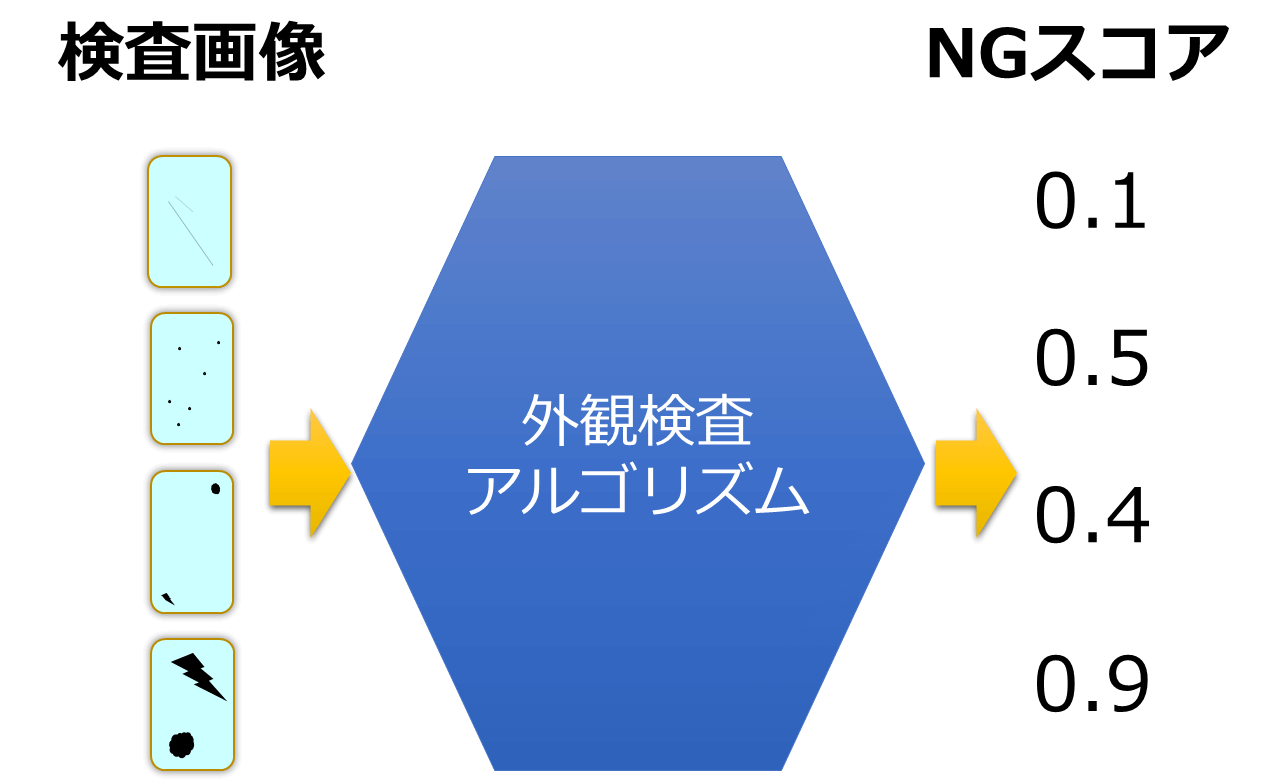
ラベル付けを行った画像データをもとにアルゴリズム開発を進めます。
外観検査アルゴリズムはNGの程度を数値(以降、NGスコアと呼びます)で出力できるものが望ましいです。
この NG スコアですが、(検査基準にもよりますが)例えば検出した不良個所の面積等が考えられます。
評価画像データに対する不良の確率のようなものでもよいと思います。
開発したアルゴリズムは評価が必要です。
OK/NG/グレーゾーンの評価画像データを使って外観検査アルゴリズムを評価していきましょう。
OK/NG とラベル付けされた画像データは誰が見ても OK/NG で、判断に迷うものが含まれていないので外観検査アルゴリズムでも確実に見分けたいところです。
外観検査アルゴリズムで確実に OK と NG を見分けられているかを評価したいので、これまでのように Accuracy/Recall/Precision などの指標を用いて評価します。
一方、グレーゾーンの画像データはラベルの判定が分かれるものが含まれています(例:10人中6人がNGと判定)。
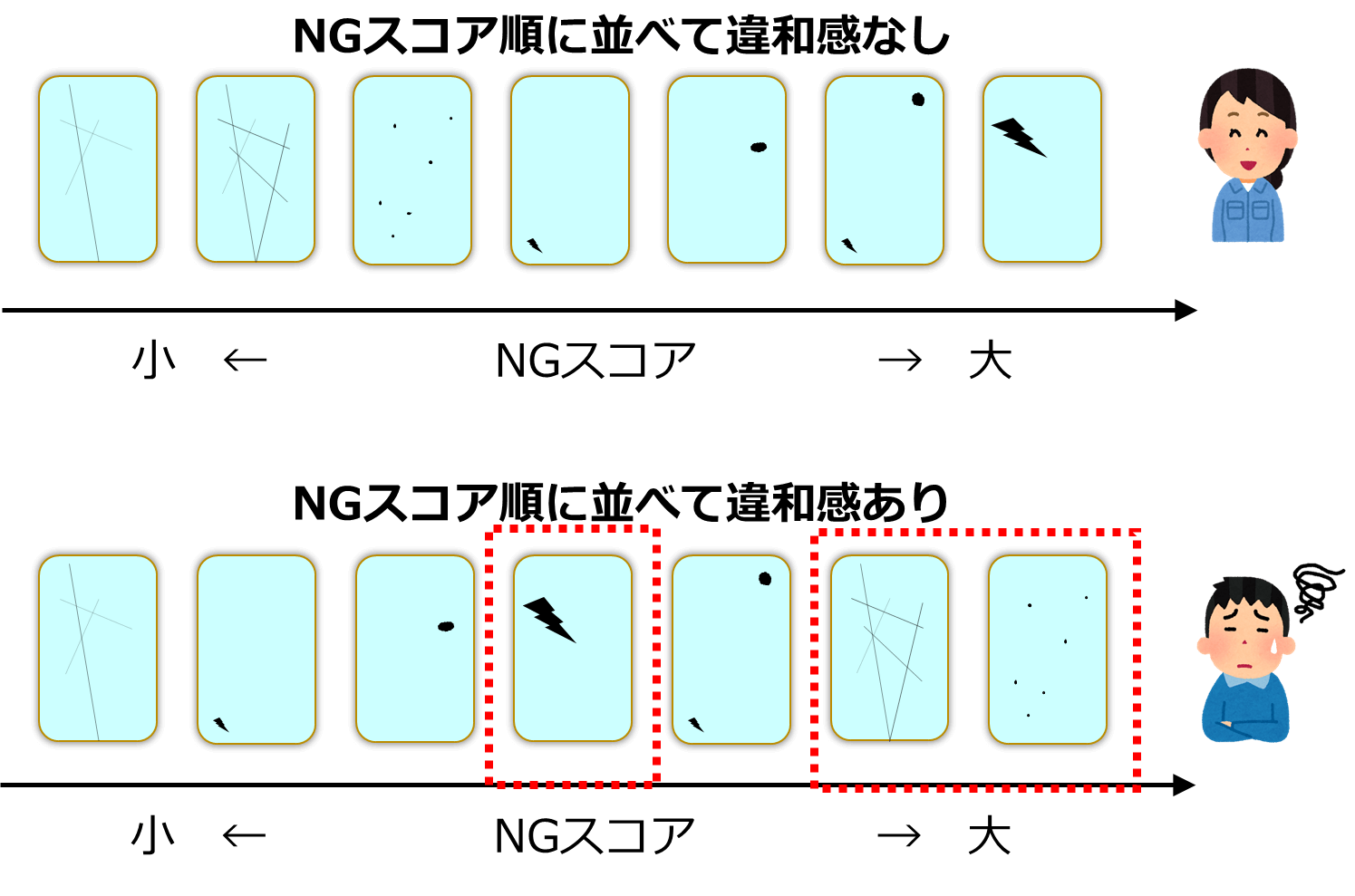
ラベルが確率的に決まるグレーゾーン評価画像データに対して、一意にラベルが決まることを前提としている Accuracy/Recall/Precision などの指標を用いた検査アルゴリズムの正確な評価は困難です。ではどうすればよいかというと、NGスコア順に並べたグレーゾーン評価画像データに大きな違和感がないかを確認するとよいでしょう。明示的な評価指標はまだ見つけられてはいませんが、NGスコアが高ければNGっぽい、NGスコアが低ければOKっぽいという感じです。この作業が人間による官能検査と機械による検査の判定基準のすり合わせになると考えられます。「NGスコアは高めなのにOKっぽいよね」とか「NGスコア低いのにNGっぽいところがあるよね」という違和感があれば、外観検査アルゴリズムの見直しが必要かもしれません。
複数人でラベル付けを行った場合は、NG ラベル数の順序で並べた評価画像データと大きな違いがないかを評価基準としてもよいと思います。
確実な正解がないのがグレーゾーンの特徴です。
しかし、運用が始まると現場での調整に一番苦労するのもグレーゾーンです。
ここでグレーゾーンの画像データを違和感なく並べられるアルゴリズムが開発できると外観検査の完全自動化に大きく近づきます。
グレーゾーンの並びに違和感がある場合は、グレーゾーンを検査員で検査する人と機械のハイブリット検査を検討してもよいかもしれません。
外観検査アルゴリズム開発の肝は、グレーゾーンの画像データをどれだけうまくNGスコア付けできるかといってもよいでしょう。
まとめ
本記事では判定の難しいケースをグレーゾーンと呼び、詳しくみてきました。
グレーゾーンは、大量の画像データを人間がラベル付けするときに人間の判断に揺らぎ・ばらつきに起因して発生してしまうこと、
グレーゾーンを多く含む画像データを外観検査アルゴリズムで判定する課題は「画像データに対するOK/NGの分類問題」ではなく
「画像データに対するNGの確率(人がNGと判定する確率)を推定する回帰問題」ととらえると良いこと、を説明しました。
外観検査アルゴリズムの評価の際、明らかなOK/NG画像データに対してはAccuracy/Recall/Precision などの指標で精度評価を行うこと、
グレーゾーン画像データに対しては Accuracy/Recall/Precision などの指標ではなく、外観検査アルゴリズムの出力するNGの程度(NGスコア)順に並べた時に
違和感がないことを確認することが重要であると紹介しました。
本記事を参考にして、外観検査アルゴリズム開発を効率的に進めてもらえると嬉しいです。
無料検証申し込み・お問い合わせ
無料検証のお申し込み、製品の購入に関するお問い合わせや御見積依頼については以下よりお願いします。

営業時間:10:00~17:00(ただし、土曜日、日曜日、祝日、当社指定休業日は除く)
- 記載されている会社名、製品名および名称は各社の登録商標または商標です。
- お問い合わせや資料請求にて取得した個人情報もしくはそれに準ずる情報の取り扱いは弊社(株)システム計画研究所の個人情報取扱方針に従います。